The Pace of Change
This paper from Nature is making the rounds online. It's an RCT in which participants got to use one of three chatbots to identify health conditions and decide on a course of action across ten medical scenarios. The results were underwhelming and LLM-assisted participants performed no better than the control group.
It has spurred headlines like this from the NYT:

and this tweet from Eric Topol:
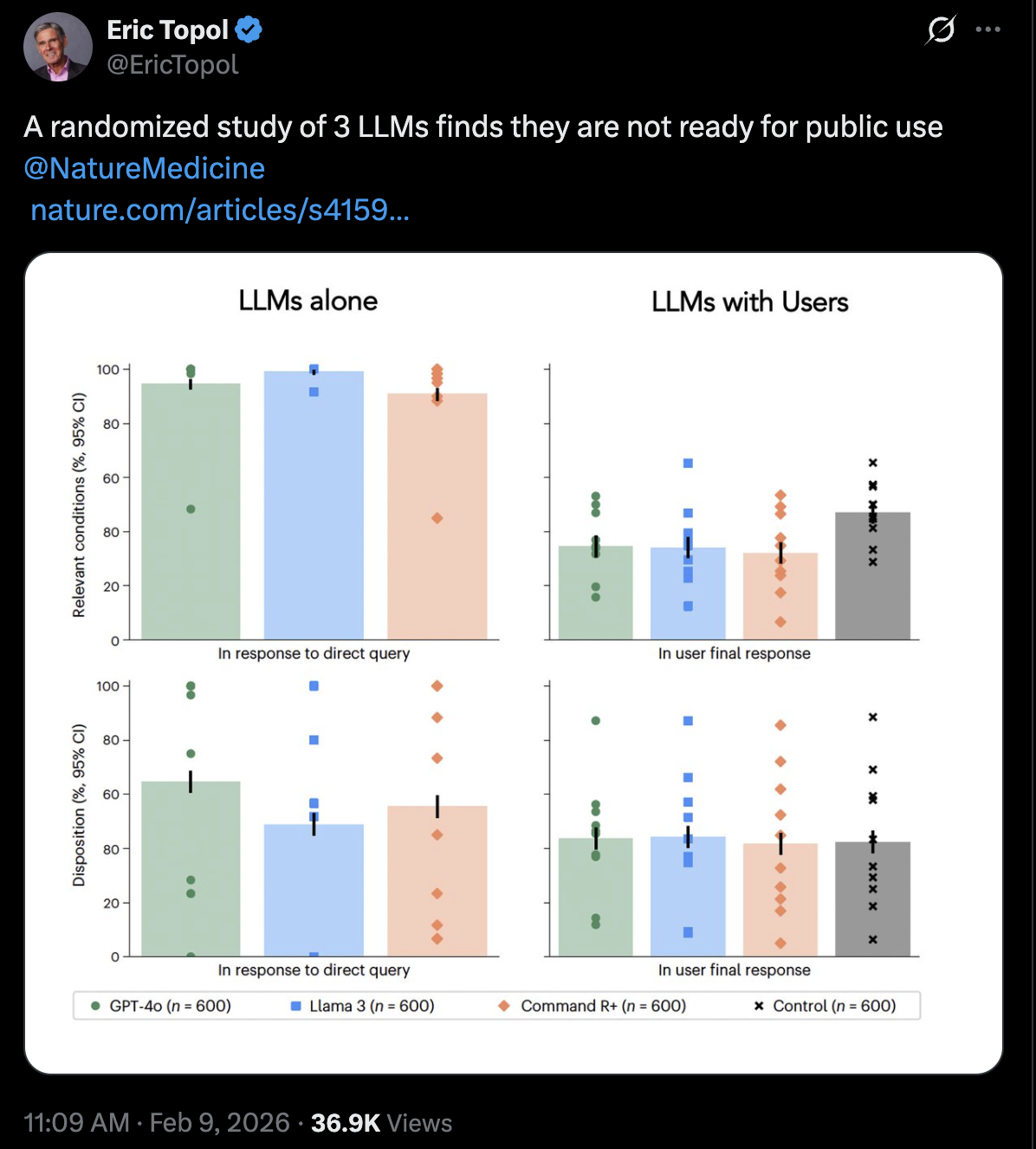
A major issue becomes apparent if you actually read through the paper. The LLMs used are generations behind the frontier, and wtf is Command R+? The only frontier lab LLM that was used in the study (GPT-4o) was notoriously sycophantic and spurred its own cult of enamored users who protested and mourned its deprecation. The authors cite sources from 2023 to claim that AI-assisted clinicians perform no better than clinicians alone. Assuming that the cited study used the most advanced models at the time, this was before reasoning models and likely says little about frontier capabilities today. This study reveals that our current research infrastructure is incapable of evaluating AI medical interventions at the pace they evolve. We need to do better, to think outside of current systems, in order to actually deliver effective and democratized medical intelligence to all.